RAG (Retrieval-Augmented Generation, 檢索增強生成),一種拿來「微調」大型語言模型的一個技術。
而 RAG 一定都會搭配一個叫做詞嵌入模型(Embedding Model),詞嵌入模型雖然也是語言模型,但我們只會拿他來將我們輸入的文字,轉換成詞向量,詞向量可以想像成一個陣列中,含有許許多多的浮點數,這些浮點數,會被拿來用來做像似度判斷。
整個 RAG 的流程可以參考以下流程圖
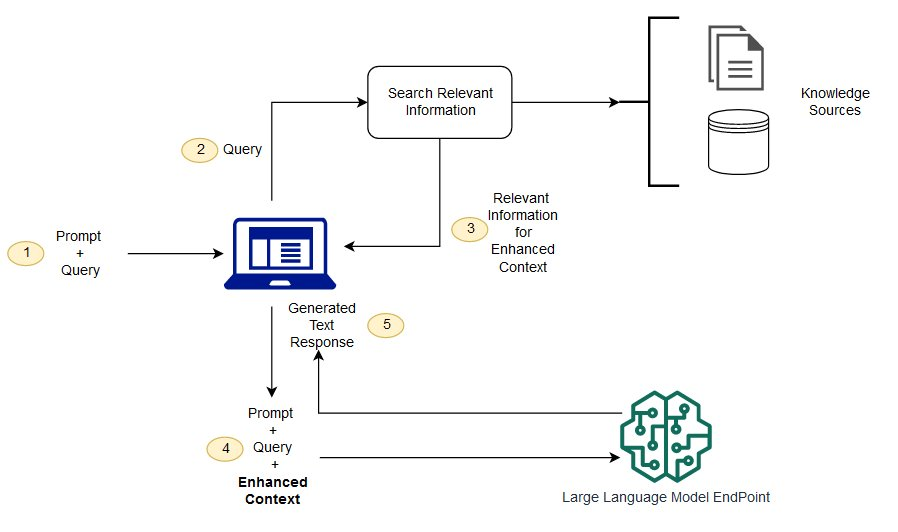
可以看到一開始當然要先輸入問題,這時我們的文字會被轉換成詞向量,並且在眾多的資料中,找出與我們詢問的問題相近的搜尋結果,在由大型語言模型處理,並且輸出結果。
講到 RAG 就不得不提在這個技術被提出之前大家拿來微調模型的技術,LoRA(Low-Rank Adaptation),其特色是可以在硬體資源相對不足的情況下,去微調出針對特定問題,有對應的解法的一個技術,若不使用lora就只能使用模型原有的知識,去回答問題。
若將 RAG 與 LoRA 技術去做比較,可以整理出以下表格
| RAG | LoRA | |
|---|---|---|
| 正確率 | 中低 | 高 |
| 方便性 | 高 | 低 |
| 兼容性 | 高 | 低 |
以上兩個技術,都非常依賴你給予的資料的品質,如文字排版,模型效能等等因素,簡單說,求穩定,就使用 LoRA ;求方便,就使用 RAG。
加上本系列推崇使本地大型語言模型及這兩項技術,值得大家自己去玩看看。

